
Caption: Medical hallucinations in LLMs organized into 5 main clusters (Kim et al., 2025)
Imagine relying on AI for crucial medical information, only to discover that nearly half of what it confidently tells you doesn’t exist at all. Welcome to the unsettling world of AI hallucinations.
In the rapidly evolving landscape of AI-assisted information processing, we’re witnessing a curious paradox: the same tools that promise to revolutionize our workflows are simultaneously introducing new challenges to information integrity. This first post in a series introduces Project ACVS (Academic Citation Verification System), which represents a broader approach to verifying AI outputs across multiple domains.
The Problem: AI Hallucinations in Information Systems.. even with Search
If you’ve used AI tools for research, content generation, or information synthesis, you’ve likely encountered what the AI community calls “hallucinations”—confident assertions that simply aren’t grounded in reality. While this issue affects many domains, academic citations provide a particularly clear example of the problem. Let me list a few examples I actually and not uncommonly encounter:
- Preprint confusion: AI recommends arXiv preprints instead of peer-reviewed published versions
- Author misattribution: Correctly identifying paper topics but attributing them to incorrect authors
- Title fabrication: Getting author names right but inventing paper titles
- Chronological errors: Assigning incorrect publication years
- Complete fabrications: Generating entirely fictional papers with convincing but false metadata
- Identifier errors: Providing incorrect DOIs or arXiv links
- Contextual irrelevance: Citing papers that exist but aren’t actually relevant to the research question
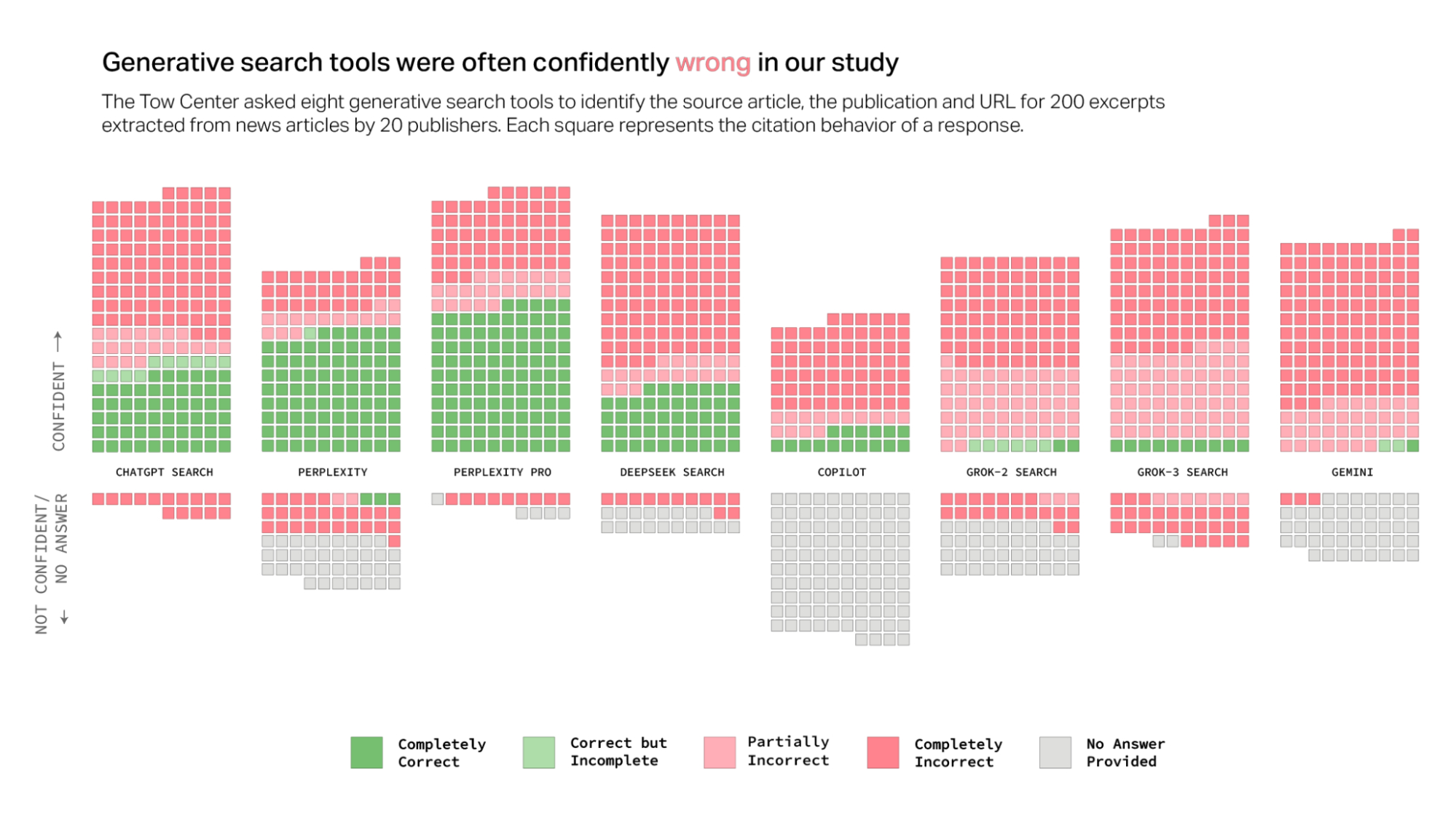 Caption: AI search does not solve but often introduces more issues to the hallucination (Jaźwińska and Chandrasekar, 2025)
Caption: AI search does not solve but often introduces more issues to the hallucination (Jaźwińska and Chandrasekar, 2025)
These aren’t just occasional glitches—they’re systematic problems. A recent study by Columbia Journalism Review’s Tow Center found that AI search engines failed to produce accurate citations in over 60% of tests, even with high confidence and convincing expressions. Recent research has quantified the scale of this problem across multiple domains, highlighting the urgent need for verification solutions:
- ChatGPT for medical content, 47% were completely fabricated, 46% contained inaccuracies, and only 7% were both authentic and accurate.
- AI tools not only fabricate non-existent papers but also introduce errors in real citations, including incorrect author names, article titles, dates, and publication details.
- Current citation tools focus primarily on formatting rather than verification: None specifically address AI hallucination verification.
- The false citation rate varies by field, ranging from 6% to 60% across different psychology subfields alone, creating convincing but nonexistent references.
- 91.8% of doctors encounters AI hallucinations in medical applications, with 84.7% believing they could impact patient health.
Note: Tow Center’s analysis may be more shocking as the issue persists even in the latest cutting-edge SOTA models and search agents (i.e., Grok 3 debuted on Feb 2025; 33 days ago as of 22 Mar 2025). Unfortunately the problem isn’t temporary or easily solved through incremental AI improvements.
Why Information Verification Matters
The problems with AI-generated citations highlight a broader issue: the need for reliable information verification across all AI systems. When AI tools hallucinate:
- In journalism, they can spread misinformation by misattributing quotes or fabricating sources
- In healthcare, they might provide treatment recommendations based on nonexistent medical literature
- In legal contexts, they could cite incorrect case law or misinterpret statutes
- In financial analysis, they may reference market data that doesn’t exist
These aren’t just minor inconveniences—they undermine trust in AI systems and can lead to serious real-world consequences.
The Root of the Problem: “Why Do AI Systems ‘Hallucinate’?”
To understand why Large Language Models (LLMs) hallucinate, we need to understand how they work. LLMs are trained on vast corpora of text. They learn statistical patterns in this text, including patterns related to factual information.
When generating content, LLMs predict text sequentially, word by word (accurately speaking, token by token). However, they face several limitations:
- No explicit knowledge representation: LLMs don’t maintain structured databases of facts; they rely on statistical correlations in their training data
- Training cutoff dates: They lack knowledge of information after their training data cutoff
- Knowledge dilution: Information about niche topics may be statistically underrepresented
- Confabulation tendency: When uncertain, LLMs tend to generate plausible-sounding completions rather than admitting ignorance
They are well known problems, and some might believe LLMs being able to search on the internet (instead of training corpus) will help. But this doesn’t appear to be sufficient solution – as proven by Columbia Tow’s analysis. Why?
Why Even AI Search Tools Hallucinate
Modern AI search engines attempt to solve these problems using Retrieval-Augmented Generation (RAG), which combines information retrieval with LLM generation. This approach is intended to reduce hallucinations by grounding responses in retrieved information, similar to how a judge might send clerks to find specific legal precedents rather than relying solely on memory.
However, RAG systems introduce their own challenges that can result in hallucinations:
-
Retrieval-Generation Gap: When the retrieved information doesn’t perfectly match what the model needs to answer a query, the LLM may fill in gaps with its parametric knowledge, leading to hallucinations. This creates a situation where the model might blend retrieved facts with generated content in ways that appear plausible but contain errors.
-
Misinterpretation of Sources: LLMs can misunderstand retrieved content. As MIT Technology Review reported in one example, an AI system cited a book titled “Barack Hussein Obama: America’s First Muslim President?” and incorrectly concluded that Obama was Muslim. The model failed to recognize the question mark and context.
-
Compound Error Problem: When retrieval systems fetch incorrect or irrelevant information, the LLM may confidently integrate this misinformation into its response, magnifying the original error.
-
Context Window Limitations: RAG systems often need to compress retrieved documents to fit within the LLM’s context window, potentially losing critical nuances or details that would prevent hallucinations.
-
Recursive Hallucination: In some advanced systems, LLMs generate their own search queries rather than using the user’s verbatim query. If these generated queries contain misconceptions, they can retrieve irrelevant documents that further reinforce the hallucination.
These challenges explain why even the most sophisticated AI search engines continue to struggle with hallucinations, despite their access to up-to-date information. The problem isn’t just about having access to facts—it’s about properly retrieving, interpreting, and integrating those facts into coherent responses. While RAG methods have been evolving, ynfortunately, there are more room to be improved than often hyped.
Enter the AI Verification Framework
The challenges outlined above led me to develop a modular verification framework, with the Academic Citation Verification System (ACVS) as its first implementation and proof of concept as well (Disclamer: this is still my personal pilot project, decoupled with any other research or projects I’ve involved professionally). The core insight is simple but powerful: while LLMs struggle with factual recall and structured data verification, they excel at other tasks that can be leveraged for information verification.
AI Verifying AI: A Fresh Paradigm
This framework represents a fascinating case of “AI verifying AI”—using specialized AI components to address problems created by more general AI systems. Rather than relying on a single monolithic model, it employs a multi-agent architecture with specialized components.
Note that “AI verifying AI” doesn’t mean creating another hallucination-prone model. Instead, we design specialized AI components that fact-check general-purpose models using structured, authoritative databases, thereby overcoming the original limitations.
System Architecture: A Four-Component Design
The verification framework is built around four core components, each handling a distinct aspect of the verification process:
- Information Extractor: Identifies and extracts claims or structured data from unstructured text
- Data Crawler: Searches authoritative sources to find matching information
- Verification Engine: Compares extracted claims against search results to identify discrepancies
- Results Processor: Organizes verification results and generates reports in various formats
In the academic citation implementation (ACVS), these components are specialized for bibliographic verification, but the architecture is designed to be adaptable to other domains.
Technical Implementation: Streamlit, Python, and APIs
From a technical perspective, the system is implemented as a Streamlit web application with a “Bring Your Own Key” (BYOK) model for API access. This approach offers several advantages:
- Rapid development and deployment: Streamlit enables quick iteration and easy deployment
- User control over costs: The BYOK model allows users to manage their own API usage
- Flexibility: Users can choose their preferred LLM provider
- Privacy: Content is processed locally when possible, with minimal data sharing
Beyond Citations: A Universal Verification Framework
While academic citations provide an excellent starting point for developing this framework, the approach generalizes to many other domains:
News Fact-Checking
The same architecture could verify factual claims in news articles or AI-generated news summaries. The Information Extractor would identify specific claims, the Data Crawler would search reliable news sources, and the Verification Engine would assess the accuracy of the claims.
Medical Information Verification
In healthcare contexts, the framework could validate AI-generated health recommendations against peer-reviewed medical literature. This could help prevent the spread of misinformation in health contexts where the stakes are particularly high.
Legal Citation Checking
The framework could verify case law and regulatory citations in AI-generated legal documents, ensuring that legal analyses are based on actual precedents rather than hallucinated ones.
Financial Data Verification
For financial analysis, the system could verify that market data, company performance metrics, and economic indicators cited in AI-generated reports actually exist and are accurately represented.
Content Attribution in Creative Fields
The framework could even help verify that AI-generated creative content properly attributes influences and doesn’t inadvertently plagiarize existing works.
The Broader Audience
This verification framework isn’t just for academics—it’s for anyone who relies on AI-generated information and needs to ensure its accuracy:
- Journalists and fact-checkers using AI to assist with research
- Healthcare professionals relying on AI for literature reviews
- Legal professionals using AI for case research
- Financial analysts leveraging AI for market insights
- Content creators using AI as a creative assistant
- AI developers building responsible systems
- Educators helping students navigate AI tools responsibly
The Road Ahead
The verification framework is still in development, with several challenges to address:
- Data source access: Authoritative sources often have access limitations or paywalls
- Source coverage: No single API covers all relevant sources for any domain
- Verification accuracy: Balancing precision and recall in information matching
- Domain adaptation: Customizing the framework for different verification tasks
In subsequent blog posts, I’ll dive deeper into the technical implementation of each component, share evaluation results, and discuss the challenges and solutions encountered in different domains. I’ll also explore how this framework can be extended to new verification tasks beyond the initial use cases.
Conclusion: A Framework for Trustworthy AI
The hallucination problem exemplifies how AI can simultaneously create new challenges and offer novel solutions. By understanding the specific limitations of current AI systems, we can design targeted verification frameworks that leverage AI’s strengths while mitigating its weaknesses.
This project demonstrates that specialized AI components can be valuable tools for maintaining information integrity in an era of AI-assisted content generation. Rather than rejecting AI tools due to their limitations, we can create ecosystems where different AI components work together—and with humans—to produce more reliable, verifiable results.
In the end, the goal isn’t just better citations or more accurate news—it’s a model for responsible AI deployment that recognizes both the potential and the limitations of these powerful technologies.
In the next post in this series, I’ll dive deeper into how I design and build the Academic Citation Verification System (ACVS), exploring how it combines various NLP techniques with LLM assistance to extract and verify structured citation data.