C, Python, and Rust take different paths to memory safety. Here’s why that difference defines the future of secure coding.
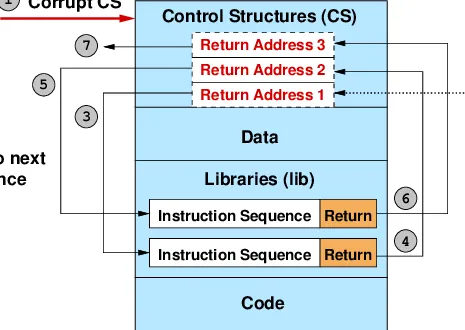
(Source: ROPdefender: A detection tool to defend against return-oriented programming attacks)
In recent years, the U.S. government has made unprecedented recommendations for the adoption of memory-safe programming languages across critical infrastructure and government systems. The National Security Agency, CISA, and other agencies have explicitly called for migration away from C and C++ toward languages like Rust, citing memory safety vulnerabilities as a primary attack vector in modern cyber warfare.
At first glance, the rationale seems straightforward: memory-safe languages prevent programmer-induced errors through automatic bounds checking, eliminating classic vulnerabilities like buffer overflows, use-after-free bugs, and dangling pointer dereferences. When a Python program attempts to access array[1000] on a 100-element array, the runtime catches the error and raises an exception rather than corrupting adjacent memory. The protection mechanism is intuitive and demonstrably effective against a broad class of programming mistakes.
However, this surface-level understanding raises a deeper, more technically challenging question about the nature of software security. Control-flow hijacking attacks operate at the lowest level of abstraction – manipulating raw assembly instructions and machine code to subvert program execution. When sophisticated adversaries craft Return-Oriented Programming (ROP), Call-Oriented Programming (COP), and Jump-Oriented Programming (JOP) exploits, they work directly with the binary artifacts that processors execute, regardless of the source language that generated them.
This raises a fundamental question that security researchers and systems programmers continue to grapple with: If all code ultimately compiles down to the same machine instructions, and attackers operate at this machine level, do memory-safe languages actually provide meaningful protection against low-level exploits? After all, a mov instruction generated by Rust looks identical to one generated by C in the final binary.
The answer, as we will demonstrate through this article, is both nuanced and profound. While the machine code itself may appear similar across languages, the conditions under which that code can be reached and the guarantees about its runtime behavior differ dramatically. Memory-safe languages don’t just generate different assembly – they generate assembly with mathematical guarantees about what states are reachable and what memory corruption is possible.
This essay examines how three representative approaches to systems programming – C’s explicit trust, Python’s runtime protection, and Rust’s compile-time verification – create fundamentally different security postures against modern code-reuse attacks, even when all ultimately execute as machine code on the same hardware.
Understanding Code-Reuse Attacks: The Fundamental Challenge
To understand why language choice matters even at the machine level, we must first examine how modern code-reuse attacks actually work. These techniques represent the evolution of exploitation in response to defensive measures – when direct code injection became difficult due to Data Execution Prevention (DEP) and Address Space Layout Randomization (ASLR), attackers developed sophisticated methods to repurpose existing code.
Return-Oriented Programming (ROP) chains together existing code fragments called “gadgets” – short sequences of instructions ending in ret instructions. By carefully crafting a sequence of return addresses on the stack, attackers can make the program execute these gadgets in sequence, achieving Turing-complete computation using only the victim’s own code.
Jump-Oriented Programming (JOP) extends this concept using indirect jumps instead of returns, providing greater flexibility in gadget selection and execution flow.
Call-Oriented Programming (COP) leverages the calling convention itself, using function calls and the program’s own control structures as the orchestration mechanism.
The key insight is that these attacks require two fundamental prerequisites: initial memory corruption to gain control, and predictable code locations to chain execution. Different programming languages provide vastly different levels of protection against both prerequisites, regardless of their final machine code representation.
Case Study 1: C’s Trust-Based Model and Its Machine-Level Implications
C exemplifies the “trust the programmer” philosophy, providing minimal runtime safety guarantees in favor of performance and predictability. While this approach enables highly optimized machine code generation, it creates systematic vulnerabilities that attackers can exploit even when working at the assembly level.
Consider this seemingly innocuous C function:
|
|
When this function executes, the stack layout becomes predictable and exploitable:
|
|
An attacker can overflow the buffer, corrupting the return address and hijacking control flow. This classic pattern underpins countless real-world exploits. From there, they can chain together ROP gadgets – small code sequences ending in ret instructions – to perform arbitrary computation:
|
|
The critical insight is that C’s trust-based model creates systematic reachability of corrupted states. The compiled assembly contains no inherent protection against reaching these states through malicious input, making the machine code itself an enabler of exploitation.
Machine-Level Analysis: When we examine the generated assembly, we observe that C compilers generate efficient code with minimal safety checks:
|
|
This assembly sequence embodies C’s fundamental problem: there are no machine-level barriers preventing an attacker from corrupting the return address. The strcpy call operates without bounds checking, and the return instruction will jump to whatever address is on the stack, regardless of its legitimacy.
Case Study 2: Python’s Runtime Protection Strategy
Python represents a fundamentally different approach – comprehensive runtime validation of all memory operations. This strategy demonstrates how higher-level language design can influence the security properties of the eventually generated machine code, even in JIT compilation scenarios.
|
|
Python’s defensive architecture creates multiple layers of protection, many of which persist down to the machine level:
Automated Bounds Validation: Every array access includes implicit bounds checking Managed Memory Model: Garbage collection eliminates use-after-free vulnerabilities Type System Enforcement: Runtime type checking prevents type confusion attacks Abstracted Memory Access: Direct memory manipulation is generally impossible
However, Python’s approach introduces unique attack surfaces that sophisticated adversaries can exploit:
JIT Compilation Vulnerabilities: Modern Python implementations (PyPy, some CPython optimizations) employ Just-In-Time compilation, creating executable code at runtime. This process can be exploited through “JIT spraying” attacks:
|
|
When the JIT compiler processes this code, it may generate machine code sequences that contain useful gadgets for ROP chains, effectively allowing attackers to inject gadgets through high-level Python code.
Garbage Collector Attack Surface: The GC itself becomes a target for sophisticated attacks. Attackers can exploit:
- Timing vulnerabilities during collection phases
- Heap feng shui techniques to arrange objects in predictable patterns
- GC metadata corruption in implementations with unsafe GC roots
Native Extension Boundary: Python’s extensive ecosystem relies on C extensions, reintroducing C-level vulnerabilities:
|
|
Machine-Level Implications: Python’s bytecode interpretation and JIT compilation create a complex execution environment where traditional static analysis becomes difficult. The runtime nature of protection means that some attack vectors remain viable if attackers can influence the runtime state.
Case Study 3: Rust’s Compile-Time Verification Revolution
Rust represents a paradigm shift in systems programming – achieving memory safety through compile-time verification rather than runtime protection or programmer discipline. This approach creates machine code with mathematical guarantees about reachable states, fundamentally altering the attack surface available to adversaries operating at the assembly level.
|
|
Rust’s fundamental innovation lies in its ownership system and borrow checker – compile-time analyses that mathematically prove memory safety properties before code generation. This creates machine code with unprecedented security guarantees.
The Mathematical Foundation of Rust’s Safety
Rust’s safety guarantees rest on formal mathematical foundations that prove two critical properties:
Spatial Memory Safety: No memory access can occur outside the bounds of allocated objects. This is enforced through compile-time bounds analysis and ownership tracking, mathematically guaranteeing that buffer overflows are impossible in safe Rust code.
Temporal Memory Safety: No memory access can occur after an object has been deallocated. The borrow checker performs a sophisticated dataflow analysis that proves no dangling pointers can exist at runtime.
These guarantees have been formally verified in projects like RustBelt, which provide machine-checked proofs of Rust’s type system. The proofs demonstrate that well-typed Rust programs cannot exhibit undefined behavior related to memory access – a mathematical certainty rather than a best-effort attempt.
|
|
This system eliminates the initial corruption vectors that enable code-reuse attacks:
- Buffer Overflows: Prevented by compile-time bounds analysis
- Use-After-Free: Eliminated through lifetime tracking
- Double-Free: Impossible due to RAII and move semantics
- Dangling Pointers: Caught during compilation by borrow checker
Machine-Level Analysis: Rust’s compiled output demonstrates how compile-time verification translates to secure machine code:
|
|
Elimination of JIT Attack Surfaces: Unlike Python, Rust compiles to native code ahead-of-time, completely eliminating JIT-based vulnerabilities:
|
|
Predictable Yet Secure Memory Layout: Rust maintains C-like performance and predictability while eliminating corruption vectors:
|
|
Comparative Analysis Against Code-Reuse Attacks
Having examined each approach individually, we can now perform a systematic comparison of their effectiveness against specific attack vectors:
Return-Oriented Programming (ROP) Defense
C: Fundamentally vulnerable. The trust-based model provides no barriers to initial memory corruption, and predictable stack layouts enable straightforward ROP chain construction. Machine code contains no inherent protection against return address corruption.
Python: Runtime bounds checking prevents most buffer overflows that enable ROP, but JIT compilation can introduce new gadgets, and native extensions reintroduce C-level vulnerabilities. The protection is reactive rather than preventive.
Rust: Multiple defensive layers – compile-time prevention of initial corruption, integrated bounds checking in generated machine code, and controlled panic mechanisms that prevent exploitation even when unexpected states are reached.
Jump-Oriented Programming (JOP) Defense
C: Vulnerable through corrupted function pointers, virtual function tables, and any indirect jump targets. Attackers can leverage predictable memory layouts to control jump destinations.
Python: Object model abstraction provides some protection against direct pointer corruption, but JIT compilation creates dynamic indirect jump targets that sophisticated attackers can potentially exploit.
Rust: Type system mathematically guarantees the validity of all function pointers and indirect jumps at compile time. No runtime code generation eliminates JIT-based gadget injection vectors.
Call-Oriented Programming (COP) Defense
C: Highly vulnerable – corrupted function pointers and return addresses directly enable COP attacks. The absence of call-site validation makes exploitation straightforward.
Python: Call mechanism abstraction provides some protection, but native extension boundaries and potential GC vulnerabilities can still be exploited by sophisticated COP attacks.
Rust: Comprehensive call-site safety through type system verification. Foreign function interface calls are explicitly marked as unsafe, localizing potential vulnerabilities to auditable code sections.
Practical Implications and Limitations
Rust’s Controlled Vulnerability Surface
Even Rust’s comprehensive approach has carefully defined boundaries where safety guarantees are relaxed for performance or interoperability:
|
|
Foreign Function Interface (FFI) Boundaries: Interoperability with C libraries can reintroduce traditional vulnerabilities:
|
|
The critical insight is that Rust makes unsafe operations explicit and localized. Security vulnerabilities can only exist in clearly marked regions, making security auditing tractable and focused.
Addressing the Original Question
Returning to our central question: Do memory-safe languages provide meaningful protection against low-level exploits when all code compiles to similar machine instructions?
The answer is definitively yes, but the protection mechanisms are more sophisticated than intuitive bounds checking. The security benefits manifest in several ways:
State Space Restriction: Memory-safe languages mathematically constrain the set of reachable program states. Even though the machine code may look similar, the conditions under which vulnerable states can be reached are fundamentally different.
Corruption Prevention: Rather than detecting corruption after it occurs, compile-time verification prevents the initial memory corruption that enables code-reuse attacks.
Attack Surface Reduction: By eliminating entire classes of vulnerabilities at the language level, memory-safe languages force attackers to find increasingly sophisticated and narrow attack vectors.
Verification Guarantees: The machine code generated by memory-safe languages comes with mathematical proofs about its runtime behavior – proofs that simply don’t exist for traditional systems languages.
The Evolution of Attack Strategies
As memory-safe languages gain wider adoption, sophisticated attackers are adapting their techniques to work around these protections. Understanding these evolving attack patterns helps illustrate both the effectiveness of memory safety and the continuing challenges in comprehensive security.
Post-Memory-Safety Attack Vectors
Logic Flaws and Business Logic Exploitation: With memory corruption eliminated, attackers increasingly focus on application logic vulnerabilities that exist regardless of memory safety. These include authentication bypasses, privilege escalation through intended functionality, and algorithmic complexity attacks that cause denial of service through legitimate operations.
Supply Chain and Dependency Attacks: Memory-safe languages rely heavily on package ecosystems (crates.io for Rust, PyPI for Python). Attackers now target these supply chains, introducing malicious dependencies or compromising existing packages – a threat vector that memory safety cannot address.
Side-Channel Attacks: Timing attacks, cache-based side channels, and speculative execution vulnerabilities (like Spectre and Meltdown) operate below the abstraction layer where memory safety provides protection. These attacks remain viable regardless of language choice.
Interoperability Boundaries: As noted with Rust’s unsafe blocks and Python’s C extensions, the interfaces between safe and unsafe code create concentrated attack surfaces. Sophisticated attackers increasingly focus on these boundary conditions.
The Security Economics of Memory Safety
The widespread adoption of memory-safe languages fundamentally alters the economics of vulnerability research and exploitation:
Increased Discovery Costs: Finding exploitable vulnerabilities in memory-safe codebases requires significantly more expertise and time investment, raising the barrier to entry for attackers.
Reduced Exploit Reliability: Even when vulnerabilities exist, they are often harder to exploit reliably, reducing the value of individual vulnerabilities in exploit markets.
Attack Vector Concentration: As traditional memory corruption vectors disappear, remaining attack vectors become more valuable but also more heavily defended and monitored.
This economic pressure drives a natural evolution in the threat landscape – from broad, automated exploitation of common vulnerability patterns toward targeted, sophisticated attacks against specific high-value targets.
Implications for Security Architecture
These findings have profound implications for how we approach systems security:
Defense in Depth Evolution: Memory-safe languages represent a fundamental shift from reactive to proactive security measures. Rather than detecting attacks in progress, they prevent the conditions that enable attacks from arising.
Economic Disadvantages to Attackers: The cost of finding and exploiting vulnerabilities increases dramatically when attackers cannot rely on traditional memory corruption techniques. This economic pressure drives attackers toward more sophisticated but less scalable attack methods.
Critical Infrastructure Protection: The US government’s recommendations for memory-safe languages are technically sound – these languages provide quantifiable security improvements against the most common and dangerous classes of vulnerabilities.
Strategic Security Planning: Organizations must balance the immediate security benefits of memory-safe languages against the evolving threat landscape. While memory safety eliminates many attack vectors, it also concentrates attacker attention on remaining vulnerabilities.
Conclusion: The Mathematical Foundation of Modern Security
The distinction between memory-safe and memory-unsafe languages extends far beyond surface-level programmer convenience. At the deepest technical level, these languages create fundamentally different mathematical relationships between source code, compiled output, and runtime behavior.
C’s trust-based model generates efficient machine code but provides no guarantees about reachable states. Python’s runtime protection creates safe execution environments but introduces new attack surfaces through dynamic compilation. Rust’s compile-time verification produces machine code with mathematical proofs about memory safety – proofs that hold regardless of input or runtime conditions.
When sophisticated adversaries operate at the assembly level, they still face the constraints imposed by these higher-level language design decisions. Memory corruption attacks require memory corruption to be possible. Control flow hijacking attacks require control flow to be corruptible. Code-reuse attacks require the ability to reach corrupted states that enable gadget chaining.
Memory-safe languages – and Rust in particular – don’t just make programming easier or reduce bugs. They create mathematical impossibilities for entire classes of attacks, even when those attacks operate at the machine code level. The machine instructions may look similar, but the guarantees about what sequences of those instructions can be reached are fundamentally different.
However, this success also drives attackers toward increasingly sophisticated techniques – logic flaws, supply chain compromises, and side-channel attacks. Memory safety is a crucial component of defense in depth, but not a complete solution to the broader challenge of software security.
In an era where nation-state actors and sophisticated criminal organizations invest heavily in finding and exploiting software vulnerabilities, the choice of programming language becomes a strategic security decision. Therefore, I believe the US government recommendations reflect not just policy preferences, but rigorous technical analysis of how language design translates to security properties at every level of the computing stack – while acknowledging that the threat landscape continues to evolve in response to these defensive improvements.